ISIS and BGP Design
Hello, and Welcome! To IS-IS and BGP design.
When I first saw that Cisco put IS-IS and BGP on the CCDA exam, I thought, there’s no way. IS-IS is a little known protocol not even designed to use the TCP/IP stack, and BGP. I mean BGP is the routing protocol of the internet! Service provider networks, transit autonomous systems, millions of routes! It’ll make your head explode. There’s no way we can cover either in depth in a general design series, especially not at the CCDA level!
And well I found that Cisco is not looking for any kind of depth here. We’ll probably be going into both of these protocols deeper than is needed but they’re both very cool and exciting to work with. In this video we’ll be covering an overview of how IS-IS works from a design perspective and what a scaled network looks like. We’ll also be going over some key ideas about BGP and how it might look to use that as an interior gateway protocol. So let’s get started.
ISIS qualities
- Link state protocol
- Designed for the OSI protocol suite
- Uses areas in a similar manner as OSPF
- neighborship forms at layer 2
Most people when they earn their CCNA and are learning about routing protocols, you learn there’s 2 types. Distance vector and link state protocols. So in distance vector you have RIP, EIGRP, and BGP, and in the link state side you have OSPF, and usually really small they’ll include IS-IS because nobody wants to try and unpack the bag of holding that is IS-IS. Well, just like you may have learned then, IS-IS is a link state routing protocol and it was designed for the OSI protocol suite. Now you may say , ‘wait, don’t you mean OSI model?’ no, so back when TCP/IP was in its infancy it had a competitor, the OSI protocol stack. Just like if anyone remembers Betamax or laserdiscs? Back when VHS was first coming out, those were really the better medium, but for whatever reason VHS won out. Well, this is very similar honestly, OSI feels like the better protocol stack in my opinion although it’s a bit more complicated.
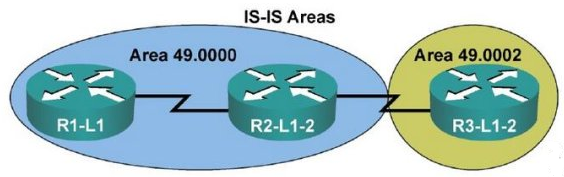
So IS-IS was the routing protocol at the time that was developed for the OSI protocol suite, but it was designed in such a way that it was highly extendable. It had it’s basic functionality but also allowed for TLV fields, that’s ‘type length value’ where you can define arbitrary information in those fields. So because of this, IS-IS was easily converted, or integrated for use with IP routing and the resultant protocol was called ‘integrated IS-IS’. Now before I get too far, let be explain briefly. In OSI, routers are called intermediate systems, and hosts like workstations or servers are called end systems, hence IS and ES. Now IS-IS uses the concept of areas just like OSPF, and actually it uses the same algorithm to calculate the best path around the network, Dijkstra’s ‘shortest path first’ algorithm. However there’s no such thing as an ABR because all routers are wholly in a single area and are not split, the boundary is on a link rather than a router, but we’ll get into hat a bit more in a moment.
The OSI equivalent to an IP address is an NSAP address, that’s network service access point. Each router has a single NSAP address, and neighborships for IS-IS form at layer 2, so only for routers on the same segment.
Now, like I mentioned a moment ago, the routers in IS-IS are always wholly within a single area, there are not any area border routers like with OSPF. However, there are 2 different databases or types of routers and that’s level 1 routers and level 2 routers. In this way IS-IS is a hierarchical routing protocol. Level 1 routers only contain the link state database for the area they are within. There’s a L1/L2 router, which is a lot like or ABR in OSPF, which contains both he link state database for level 2 and of the area for which it is a level 1 router. The level 1 routers in the area have no knowledge of the L1 database, they just know how to get to the nearest L1/L2 router in the area. The L1/L2 routers have the ability to summarize their area’s network into the L2 database. The L2 routers are intended to be the network backbone. That rather than having an area 0, you have L2 routers. However it’s a lot more extendible. You can have multiple backbones if your design ends up that way.
One of the major issues with using IS-IS as an interior gateway protocol is that it requires a fair bit of manual tuning. As far as IS-IS is concerned, all links have a cost of 10. Just 10-. Basically just hop count, we’re getting like into RIP world here. So you as the network admin will need to go into each and define a cost for each link, you’ll likely have your spreadsheet with link speeds to cost and apply that to each link in IS-IS. It’s more manual, but because of the TLV fields, it’s no extendible that it keeps on coming in handy and really works well and is overall much more flexible than OSPF.
Another note is that currently IS-IS doesn’t support anything but cleartext authentication. There’s a draft for an RFC to modify IS-IS to use only MD5 authentication, but at this time that hasn’t bee published yet to everything’s still cleartext.
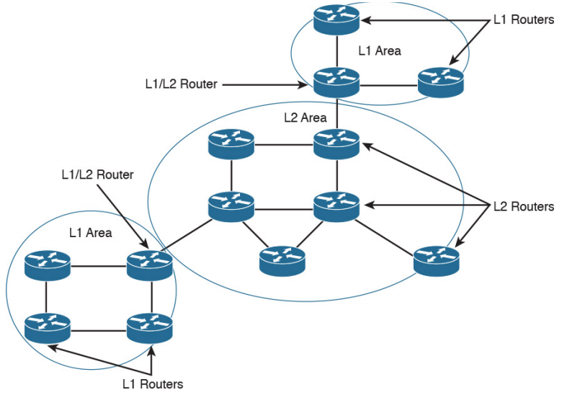
So like I mentioned, the backbone of IS-IS is the L2 routers. There’s not a backbone area like OSPF’s area 0. The ‘backbone’’ of IS-IS is a continuous path of adjacent L2 routers. These are intended to be the spine to your sine and leaf topology and truly act like a backbone. The L1/L2 routers which are like the ABRs of IS-IS don’t flood any link updates into their area they are part of, that includes L2 and any other L1 areas. Here we have an example I got from the CCDA cisco press book showing a sample IS-IS design. You can see it’s set up very much like OSPF with your areas, an L1 area in the bottom left and top right with a backbone L2 area in the middle. If your network is large enough, you may have a line of only L2 areas, however often people opt for just connecting a bunch of L1/L2 routers together because your network has to be rather large to benefit from having only L2 routers.

Now here we are to the big wooly mammoth and all powerful he-man that is BGP. BGP is the routing protocol of the internet, if you didn’t know. It’s what ISPs use to exchange routes and generally what is used to keep track of the millions of routes that make up the internet as we know it. This is really for a few reasons. First, it’s rather slow. You can imagine what might happen if the world used something like OSPF, the routers of the world would explode! With an insane number of LSAs being flooded into the worlds’ routing areas every second it would be impossible to handle the amount of information that’s being transferred. So BGP, when it sees a network go down, it sits and waits a moment and sees if it comes back up.
Well, okay, so as far as BGP on the CCDA goes, we’re not really talking about the world’s service provider routing, we’re talking about using BGP as an IGP. iBGP has a default hello timer of 60sec, and a hold timer of 3x that. A long time, right?
Now, when I say using BGP as an IGP, I mean specifically using iBGP, which means peeing BGP routers with other routers that use the same autonomous system number. See BGP at it’s core uses autonomous system numbers to prevent loops, because it’s dealing with the world’s routing tables, right? So there’s thousands and thousands of autonomous systems out there, and the way it works is that when a route is advertised with BGP, it’s stamped with eh AS it came from, and it’s stamped each time it leaves an AS. If it ever returns to an AS that it has a stamp for, it won’t be learned by that router. This is ghreat when you’re talking about a worldwide routing protocol, but the issue comes in when you’re using iBGP because all of your routers are in the same AS.
Most of the time you’ll be using BGP to interface with service providers, either in an MPLS circumstance, or you may be using BGP to advertise your public IP out multiple service providers so that some publicly facing server you host will be accessible even if one of your service providers goes down. However, sometimes your company may decide to go with BGP as an IGP, and there’s definitely some arguments both for and against this decision.
First, let’s go over the positives here. One reason to use BGP is because it’s an industry standard. If you have a quote ‘real router’ it’s almost certainly going to support BGP. Now, when I say a cisco router, you can be pretty certain that it will support BGP, Cisco routers are not low end routers for the most part. Some of the small business class routers in the SG series or something may not support BGP but that’s about it.
BGP also allows per-hop traffic engineering. For those of you that like to tweak and really get something to work exactly the way you want, this is for you. You can get down to the very granular levels and truly define exactly how traffic is handled at each and every hop.
BGP also allows for unequal cost load balancing like EIGRP, but oh, it’s also the holy grail, anycast routing. So what anycast routing is, is one to closest routing. So DNS providers do this a lot, right, where they have 1 IP, but by some black magic regardless of where you are in the world their servers are always within 10ms of you. This is done by standing up servers in multiple parts of the world and assigning them the same IP address. And I know the network admin in you is curling up and saying this isn’t possible, but BGP is designed for huge amounts of redundancy and multipathing and this is totally possible. So you will always find the closes source of the IP you’re looking for.
Now also along the lines of BGP being kinda slow, it can also do batched updates, so if you have a circumstance where you want to control flooding and be sure you don’t overwhelm a router, you can set BGP to send batched updates at a certain interval to avoid that. Finally what really might be the most important benefit is that BGP provides the ultimate control in sending and receiving routes. With OSPF and EIGRP they really want to receive anything that’s given to them, but that’s not the case with BGP. There’s actually been cases where ISPs have caused major regional outages in the world because somebody made a mistake and advertised out routes that were unintentional and incorrect. With BGP, you can easily and built into the protocol control the routes that you learn from your neighbors. This is great when you’re interfacing with another department, or say even an acquisition or another vendor and you want to be absolutely sure you only receive the routes you expect.
Now, moving to the other side here, BGP by default is rather slow, if you want that ninja fast subsecond failover, it’s not for you. Also, it’s really only available on ‘real’ routers, and because of that a lot of your L3 switches don’t support it and your lower end routers also will likely not support BGP.
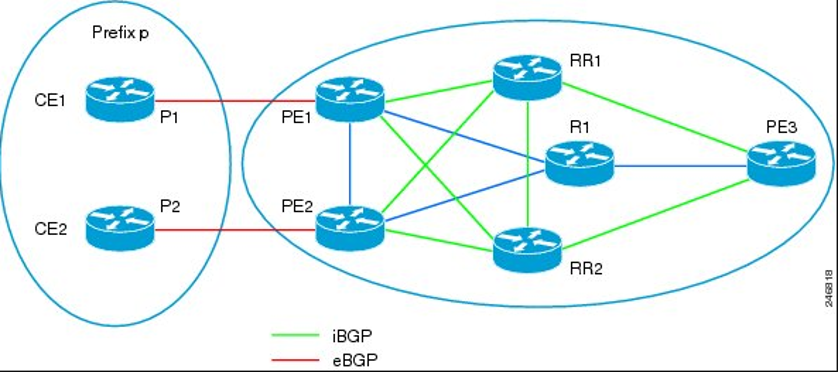
Now also, at it’s core, BGP is intended to be the routing protocol of the world, so it’s meant to not be real granular in how it determines its path, so by default it uses the shortest AS path. This doesn’t take into account the bandwidth or anything of the links themselves at all. So you don’t really have that dynamicness of OSPF or EIGRP, it takes a lot more manual work to ensure you get optimal routing throughout your network. And this will lead into the next slide explaining this, but it requires full mesh connectivity to its neighbors when used as an IGP.
See, since BGP has a rather simple routing loop prevention mechanism based around AS path; this breaks down when all the routers are in the same AS. So what does it do instead? It has a rule stating that if a route is learned via iBGP, then that route cannot be advertised out via iBGP. So it’s basically a 1 time advertisement, right? That’s called BGP split-horizon and that’s why there’s the full mesh requirement, because otherwise your routes wouldn’t propagate to the whole system.
Now this is fine, but at a point it gets a little unruly. Since BGP neighbors are only ever statically set, you’ll need to add another neighbor to each router in the AS each time a new router is added and you’ll end up with potentially hundreds of neighbors. There’s 2 was to get around this, route reflectors, and confederations.
First, a route reflector is when you go into BGP configuration and essentially disable split horizon for some of the neighbors, setting route reflector clients to which that router is allowed to re-advertise the routes learned via iBGP. This can really control your full mesh requirement and be very useful when executed correctly such that you don’t accidentally create routing loops. This is a totally valid method, although it’s a little less intentional and takes less planning than confederations.

A confederation takes your AS that all of the routers are part of and puts them into sub autonomous systems. Of course you can immediately see that this gets around the split horizon issue by putting routers into a bunch of different autonomous systems. The problem with this is if you already have just a bunch of iBGP routers in a single AS, then you actually need to remove that BGP config and place the router into a new AS. So like ‘no router bgp 500’, downtime will happen. This also requires a fair bit more planning than route reflectors.
So that’s a brief flyby of BGP and IS-IS and how to plan an expansion.
Thanks for sticking with me!
© Ben Jacobson.RSS